
이상 탐지 넌 무엇이냐? #1
-
date_range 05/02/2020 18:26 perm_identity 박상민 infosortPaperlabel
본 내용은 2018년 한국보건사회연구원 에서 출간한 ‘기계학습(Machine Learning)기반 이상 탐지(Anomaly Detection)기법 연구- 보건사회 분야를 중심으로’ 연구보고서를 정리한 내용입니다. 원문은 여기서 확인할 수 있습니다.
1. 이상 탐지(Anomaly Detection) 개념 정의
1.1 이상 탐지 개념 및 특성
‘anomaly’는 흔히 정상(normal)의 반대 개념이며, 개념의 정의를 위해서는 ‘정상’에 대한 정의부터 내려야 한다. ‘정상’에 대한 개념은 도메인의 문제에 따라 다르게 정의될 수 있기 때문에 ‘anomaly’에 대한 개념 역시 모두 다르게 정의 될 수 있다.
Classification은 두 클래스를 구분할 수 있는 경계면을 찾는 것이라고 하면, Anomaly Detection은 다수의 클래스를 고려하여 이상적이지 않은 데이터들의 집합을 찾는 것이라고 볼 수 있다.

Anomaly Detection과 Classification의 차이
이상값은 데이터 내에서 정상적인 패턴을 따르지 않는 값을 말한다. 다음 그림을 통해 이상값과 노이즈의 차이를 확인 할 수 있다. 이상값은 데이터의 분포에서 크게 벗어난 값임을 확인할 수 있다. 반면 노이즈는 전체 데이터의 분포에서 크게 벗어나지 않은 값임을 확인할 수 있다.
노이즈는 정상적인 분석에 방해가 되기 때문에, 분석 이전 단계에서 불필요한 개체 또는 성분을 없애는 잡음 제거 과정을 거친다.
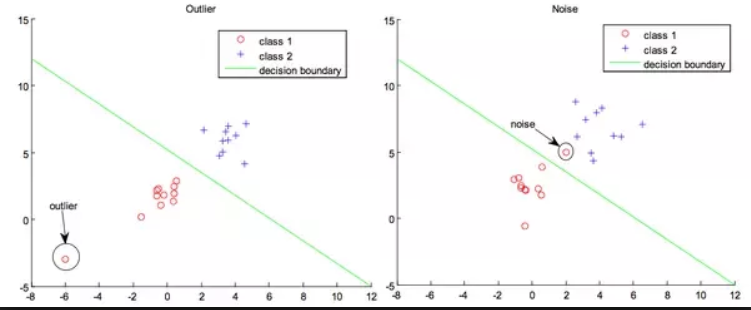
2차원 데이터에서 이상값과 노이즈 예시
이상 탐지와 비슷한 연관 분야로 신상 탐지(Novelty Detection)이 존재한다. 지금까지 발견되지 않았던 새로운 패턴을 찾아내는 것을 목표로한다. 이상 탐지와 차이점은 찾아낸 패턴을 정상에 포함한다는 것이다. 관련 내용은 추후에 다시 다룰 것이다.
이상 탐지는 시간의 특성을 가지는 Time-Series 분야에서도 연구된다. 시간을 맥락적 변수(Contextual Variable)로 보았을 때, 이상 탐지 문제의 특수한 성질은 다음과 같다.
- 시계열 자료에서는 시간의 연속성이 존재하여 특정 시점이 그 시점 전, 후의 값에 크게 영향을 받는다. 일반적으로 시간에 대한 Window Size를 적절히 선택하여 분석을 진행해야 한다. 반면, 일반적인 데이터에서는 시간적 특성에 영향을 받지 않기 때문에 특성들의 독립성을 가정하고 이상값을 탐지할 수 있다.
- 시계열 자료에서 비정상적인 시점을 찾는 것을 목표로 하느냐, 비정상적인 변화의 패턴을 찾는 것을 목표로 하느냐에 따라 분류된다.
- 과거 자료의 이상값에 대한 라벨이 이용 가능한지의 여부에 따라 지도 vs 비지도 학습으로 분류된다.
1.2 이상 탐지의 여러 요소
1.2.1 입력 데이터의 성질
데이터 내 변수들의 성질에 따라 적용할 수 있는 이상 탐지 기법또한 달라진다. 대부분 통계 모형은 연속형이나 범주형 자료에만 적용할 수 있다. 또한 k-NN 기반의 기법들을 관측값 간 거리의 정의가 추가적으로 필요하다. 특히 데이터의 실제 값 대신 거리 행렬이나 유사도 행렬과 같은 형태로 데이터 관측값 간 거리만 주어지는 경우에는 원자료 값이 필요한 대부분의 통계적 기법들을 적용하기 어렵다는 문제점이 존재한다. 또한 데이터의 특성들이 서로 상관 관계가 존재하는지에 따라 입력 자료의 특성이 분류된다.

k-NN 예시. 분류하고 싶은 관측값을 기준으로 거리를 어떻게 확정할 것인가?
1.2.2 이상의 종류
-
점 이상(Point Anomaly)
데이터 내 하나의 관측값이 나머지에 대해 이상하다고 판단되는 경우이다. 다음 그림을 통해 확인 하면, 점 O1과 O2는 영역 C1, C2내 점들 처럼 일반적인 영역에 속하지 않은 점들이다.

Point Anomaly 예시
-
맥락적 이상(Contextual Anomaly)
데이터 관측값이 특정 맥락에서 이상하다고 판단되는 경우를 말한다. 여기서 ‘맥락’의 개념을 명확히 정의해야 한다. 맥락 변수와 행동 변수를 정의하는 법은 다음과 같다.
- 맥락적 속성 또는 맥락 변수(Contextual Attribute)는 맥락 또는 그 근방을 결정한다. 대표적으로 공간 데이터의 위경도, 시계열 데이터의 시간 등이 맥락 변수이다.
- 행동적 특성 또는 행동 변수(Behavioral Attribute)는 맥락적이지 않는 특성을 나타낸다. 대표적 예로 평균 강우량, 온도 데이터가 존재할 때, 각 위치에 따른 강우량이 이에 해당한다.
이상 여부는 특정 맥락에서 행동 변수의 값으로 판단해야한다. 맥락적 이상은 시계열 데이터와 공간 데이터에서 가장 흔하게 찾을 수 있다. 다음 그림이 그 예시이다. 겨울에 기온이 낮은 것은 이해할 수 있지만, 여름 기온이 겨울 기온과 비슷하다는 것은 매우 이상한 상황일 것이다.

대상이 되는 영역에서 맥락적 이상이 얼마나 의미가 있는지와 맥락적 속성을 쉽게 구분할 수 있는지에 따라 이상 탐지 기법 적용 여부가 결정된다.
1.2.3 라벨링
라벨은 데이터의 관측값 이상 여부를 나타낸다. 전체 훈련 데이터에 정확히 이상 여부에 대한 라벨링을 부여하는 것은 아주 어려운 일이다. 특히 모든 종류의 이상을 분류하는 것은 더욱 어렵다. 또한 이상이 매우 드물게 발생하거나 새로운 종류의 이상이 등장했을 때, 새로운 종류의 이상으로 분류된 관측값을 구하는 것은 사실상 불가능하다. 따라서 라벨링되지 않은 데이터를 다룰 필요가 있고, 다루는 정도에 따라 세 가지로 나뉜다.
-
Supervised Anomaly Detection
훈련 데이터 내 모든 관측값에 라벨링이 되어있을 때 쓰이는 방법으로, 정상 또는 이상을 판단하는 분류 모형을 학습시키는 것이 가장 일반적인 방법이다. 대부분 데이터가 정상에 비해 이상의 비율이 매우 작은 imbalanced한 상태에 있고, 정확한 분류가 어렵다는 것이 특징이다. 이 특징을 제외하면 예측 모델링을 수행하는 방식과 비슷하다.
-
Semi-Supervised Anomaly Detection
훈련 데이터 중 정상 관측값에만 라벨링이 되어있고 정상/비정상 여부를 알 수 없는 관측값이 존재할 경우 사용하는 방법이다. 일반적으로 정상 데이터만을 사용하여 모델을 학습시킨 뒤 테스트 데이터에 적용하는 방식을 이용한다.
-
Unsupervised Anomaly Detection
라벨이 없는 데이터에서 사용하는 방법으로, 가장 널리 사용될 수 있는 기법이다. 주로 관측값 간의 거리를 기반으로 하여 이상값을 탐지한다. 일반적으로 정상의 비율이 압도적으로 크다는 가정이 필요한데, 이 가정을 위배한다면 오경보율(False Alarm Rate)와 같은 문제가 발생할 수 있다.
1.2.4 이상 탐지 모델의 출력값
이상 탐지 모델의 출력값을 이용해 각 관측값의 이상 여부를 판단한다. 주로 사용되는 방법으로는 각 개체마다 크기 순서가 있는 이상 점수(Anomaly Score)를 계산하는 방법과 정상 또는 이상의 라벨을 부여하는 방법이 존재한다. 이상 점수를 이용하면 정상과 이상을 구분하는 특정한 Threshold를 부여해야 한다. 이 Threshold 결정은 도메인 지식을 바탕으로 분석가가 설정해야 하는 영역이다. 반면 라벨을 부여하는 방식에서는 분석가가 모델의 Parameter 또는 Hyper parameter값을 조정하여 간접적으로 비정상과 정상의 경계를 바꿀 수 있다.